平时主要用到spark core和spark SQL(在spark之外还有MR),针对我的情况整理一下网上的知识点。
1. spark的工作机制
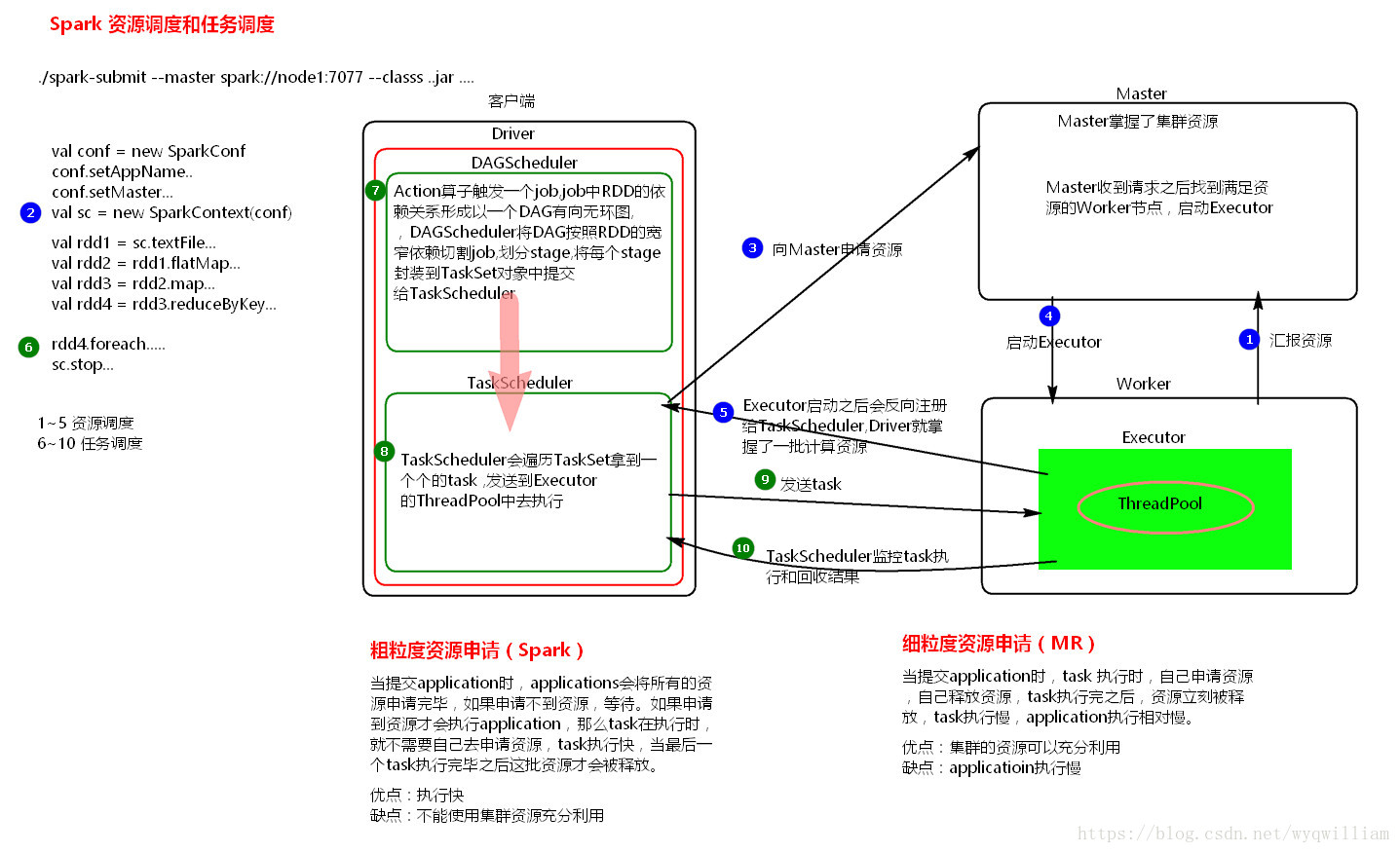
用户在客户端提交作业后,会由Driver通过运行main方法并创建SparkContext上下文,SparkContext向资源管理器申请资源,启动Executer进程,并通过执行rdd算子,形成DAG有向无环图,输入DAGscheduler,然后通过DAGscheduler调度器,将DAG有向无环图按照rdd之间的依赖关系划分为几个阶段,也就是stage,输入task scheduler,然后通过任务调度器task scheduler将stage划分为task set分发到各个节点的executor中执行。
1.1 Driver的功能是什么
一个Spark作业运行时包括一个Driver进程,也是作业的主进程,具有main函数,并且有SparkContext的实例(实例:用一个类创建的一个对象),是程序的入口点。
功能:负责向集群申请资源,向master注册信息,负责了作业的调度,负责作业的解析,生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
2. 关于DAG-有向无环图
Spark中使用DAG对RDD的关系进行建模,描述了RDD的依赖关系(lineage),RDD的依赖关系使用Dependency维护,DAG在Spark中对应的实现为DAGScheduler。
2.1 DAGScheduler中的一些概念
作业(Job):调用RDD的一个action,如count,即触发一个Job,spark中对应实现为ActiveJob,DAGScheduler中使用集合activeJobs和jobIDToActiveJob维护Job。两次action则会生成两个job,顺序提交,前一个Job执行结束之后才会提交下一个Job。
调度阶段(Stage):代表一个Job的DAG会在发生shuffle处被切分,切分后每一个部分即为一个Stage,Stage实现分位ShuffleMapStage和ResultStage,一个Job切分的结果是0个或多个ShuffleMapStage加一个ResultStage。
任务(Task):最终被发送到Executor执行的任务,和stage的ShuffleMapStage和ResultStage对应,其实现分为ShuffleMapTask和ResultTask。
3. 什么是RDD
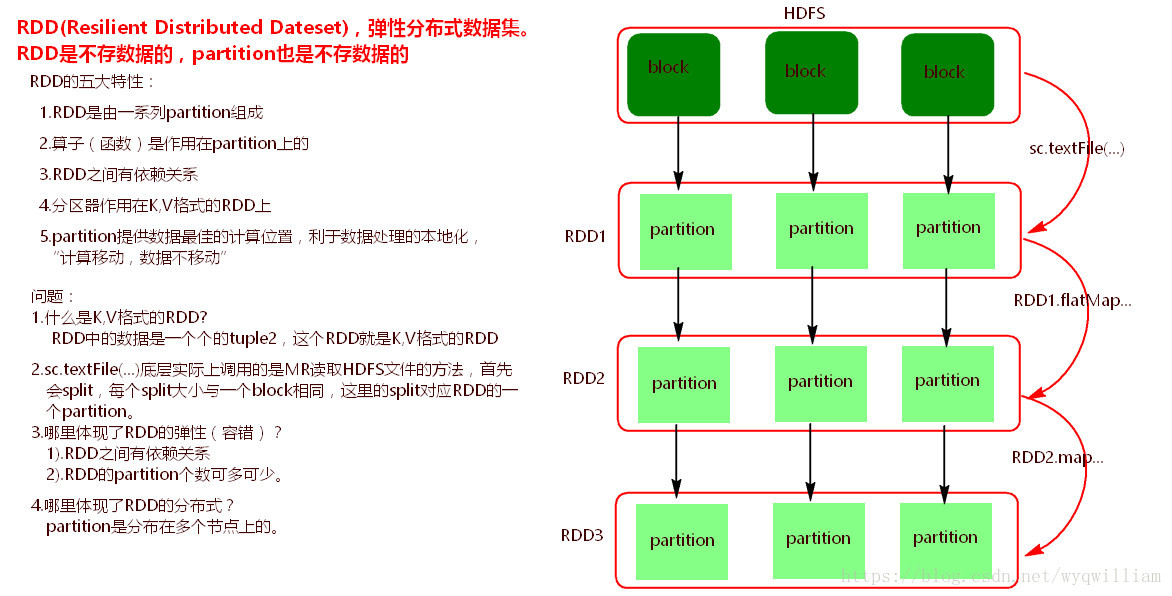
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
Dataset:就是一个集合,用于存放数据的
Distributed:分布式,可以并行在集群计算
Resilient:表示弹性的
RDD的弹性体现在: 1.自动进行内存和磁盘切换 2.基于lineage的高效容错 3.task如果失败会特定次数的重试 4.stage如果失败会自动进行特定次数的重试,而且只会只计算失败的分片 5.checkpoint(每次对RDD操作都会产生新的RDD,如果链条比较长,计算比较笨重,就把数据放在硬盘中)和persist (内存或磁盘中对数据进行复用)(检查点、持久化) 6.数据调度弹性:DAG TASK 和资源管理无关 7.数据分片的高度弹性repartion(如在计算的过程中,会产生很多的数据碎片,这时一个Partition可能会非常小,每次都会消耗一个线程去处理,这时可能会降低它的处理效率,需要考虑把许多小的Partition合并成一个较大的Partition去处理。另外,有可能内存不是那么多,而每个Partition的数据Block比较大,这时需要考虑把Partition变成更小的数据分片,这样让Spark处理更多的批次,但是不会出现OOM)
3.1 RDD的三种操作类型
(1)Transformation:进行数据状态的转换,对已有的RDD创建新的RDD。
(2)Action:触发具体的作业,对RDD取结果。
(3)Controller:对性能效率和容错方面的支持。如persist, cache和checkpoint。
3.2 RDD的宽依赖和窄依赖
窄依赖: 一个父RDD分区只被一个子RDD分区使用,一个子RDD依赖父RDD的部分分区。可精确定位依赖的上级RDD分区,选择和自己在同一节点的上级RDD分区,没有网络IO开销,高效。如map,flatmap,filter操作。
宽依赖: 一个父RDD分区会被多个子RDD分区使用,一个子RDD分区依赖父RDD的所有分区。无法精确定位依赖的上级RDD分区,相当于依赖所有分区(例如groupByKey)。计算涉及到节点间的网络传输。
narrow dependencies可以支持在同一个集群Executor上,以pipeline管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败恢复也更有效,因为它只需要重新计算丢失的parent partition即可,
shuffle dependencies 则需要所有的父分区都是可用的,必须等RDD的parent partition数据全部ready之后才能开始计算,可能还需要调用类似MapReduce之类的操作进行跨节点传递。从失败恢复的角度看,shuffle dependencies 牵涉RDD各级的多个parent partition。
3.3 RDD的缺陷
不支持细粒度的写和更新操作(如网络爬虫),spark写数据是粗粒度的所谓粗粒度,就是批量写入数据,为了提高效率。但是读数据是细粒度的,也就是可以一条条地读。(待补充)
4. Spark和MapReduce的对比
两者都是用mr模型来进行并行计算。
- 机制
hadoop的一个作业称为job。 job分为map task和reduce task,每个task都是在自己的进程中运行的。当task结束时,进程也会结束。
spark用户提交的任务称为application。一个application对应一个sparkcontext,application中存在多个job,每触发一次action操作就会产生一个job,这些job可以并行或串行执行。每个job中有多个stage,stage是shuffle过程中DAGSchaduler通过RDD之间的依赖关系划分job而来的。每个stage里面有多个task,组成taskset,由TaskScheduler分发到各个executor中执行。executor的生命周期是和application是一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存进行计算。
- Spark相比MR的优点
hadoop的job只有map和reduce操作,表达能力欠缺。而spark API中提供了大量的RDD操作如join,groupby等。
在mr过程中会重复的读写hdfs,造成大量的IO操作,多个job需要自己管理关系。而spark的迭代计算都是在内存中进行的,减少了低效的磁盘交互。
spark通过DAG图可以实现良好的容错。
代码量更少。
- 简述MR编程模型
首先map task会从本地文件系统读取数据,转换成key-value形式的键值对集合,使用的是hadoop内置的数据类型。将键值对集合输入mapper进行业务处理过程,将其转换成需要的key-value。
在输出之后会进行一个partition分区操作,默认使用的是hashpartitioner(也可通过重写getpartition方法自定义分区)。之后会对key进行进行sort排序,grouping分组操作将相同key的value合并分组输出之后进行一个combiner归约操作,其实就是一个本地段的reduce预处理,以减小后面shuffle和reducer的工作量。
reduce task会通过网络将各个数据收集进行reduce处理,最后将数据保存或者显示,结束整个job。
-
hadoop和spark的shuffle hadoop:map端保存分片数据,通过网络收集到reduce端 spark:spark的shuffle是在DAGSchedular划分Stage的时候产生的,TaskScheduler要分发Stage到各个worker的executor,减少shuffle可以提高性能 详细介绍在这里
-
hadoop和spark的shuffle相同之处
两者并没有大的差别,都是将mapper(Spark: ShuffleMapTask)的输出进行partition,不同的partition送到不同的reducer(Spark里reducer可能是下一个stage里的ShuffleMapTask,也可能是ResultTask)
Reducer以内存作缓冲区,边shuffle边aggregate数据,等到数据 aggregate以后进行reduce()。
- hadoop和spark的shuffle差异
Hadoop MapReduce是sort-based,进入combine()和reduce()的records 必须先sort。mapper对每段数据先做排序,reducer的shuffle对排好序的每段数据做归并。
Spark默认选择hash-based,通常使用HashMap来对shuffle来的数据进行aggregate,不提前排序。如果用户需要经过排序的数据,可以用sortByKey()。
5. 基础习题
- TopN问题
data.map(x=>(x,1)).reduceByKey(_+_).map(r=>r._2,r._1).sortByKey(false).map(r=>r._1,r._2) take N - dataframe根据两列排序,一列升序一列降序
val df = Seq( (2,6),(1,2),(1,3),(1,5) ).toDF("A","B") df.orderBy($"A",$"B".desc) - rdd分组排序,每组取top(N)
#主要代码 val groups=lines.groupByKey() val groupsSort=groups.map(tu=>{ val key=tu._1 val values=tu._2 val sortValues=values.toList.sortWith(_>_).take(4) (key,sortValues) }) groupsSort.sortBy(tu=>tu._1, false, 1) - 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,找出a、b中共同的url
可以估计每个文件安的大小为320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。 遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,…,a999)中。这样每个小文件的大约为300M。 遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,…,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,…,a999vsb999)中, 不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。 求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url, 看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
未完待续。有两张图挺好的,先贴在下面吧: