做一篇临时的复习,查缺补漏。
- sigmoid时,消失和爆炸哪个更易发生?
梯度消失。详解:
https://www.cnblogs.com/DjangoBlog/p/7699664.html
- sigmoid和RELU的区别?
(1)sigmoid函数值在[0,1],ReLU函数值在[0,+无穷],所以sigmoid函数可以描述概率,ReLU适合用来描述实数;
(2)sigmoid函数的梯度随着x的增大或减小而消失,而ReLU不会。
- RELU的缺点
神经元脆弱,一有小于0的输入就会导致结点死亡。输入的分布在每层都可能发生变化,一旦某层的输入变成了大多数为负的分布,则会有大量结点死亡。
| 因此有了LeakyRelu等改良(输入为负时,函数值为a* | x | ) |
- LSTM为什么能避免梯度消失
传统的RNN是用覆盖的的方式计算状态,类似复合函数。即输入x和上一层的hiddenState,用两个矩阵乘以它们并且加上常量,套上激活函数,然后在每一个时间步重复这个过程……(传统RNN详解)则求导的时候导数的展开为多个导数的乘积,容易造成梯度爆炸或消失。梯度爆炸可以解决,如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩),而梯度消失不好解决。
反观LSTM,每一时刻的状态是通过累加(前面每个时刻的状态乘以权重)的方式来计算的,如此就不是复合函数的形式了,它的的导数也不是乘积的形式,这样就不会发生梯度消失的情况了。
- GRU和LSTM的比较
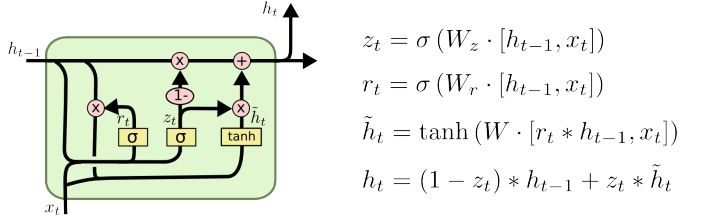
reset gate $r_{t}$ 用来控制需要保留多少之前的记忆。比如为0时,则$\tilde{h_{t}}$只包含当前词的信息。
update gate $z_{t}$ 决定需要从前一时刻的隐藏层中遗忘多少信息。
总结: GRU的参数更少,因而训练稍快或需要更少的数据来泛化。另一方面,如果你有足够的数据,LSTM的强大表达能力可能会产生更好的结果。
海量数据处理问题:
https://www.jianshu.com/p/ba86194b0b93
海量数据找中位数:
https://blog.csdn.net/randyjiawenjie/article/details/6968591
假设检验(谁叫我是数学系的呢,总是被问到这个):
https://blog.csdn.net/tianguiyuyu/article/details/80789856
堆排序:
https://www.cnblogs.com/Java3y/p/8639937.html
归并排序
bitmap:
https://www.jianshu.com/p/bf9dbbc147ed
看看归并排序 刷一两道leet,看假设检验,然后再把归并排序\堆排序写一遍