1.问题回顾
最近借阿里云一比赛的机会做了两个评论分析模型,原问题如下:
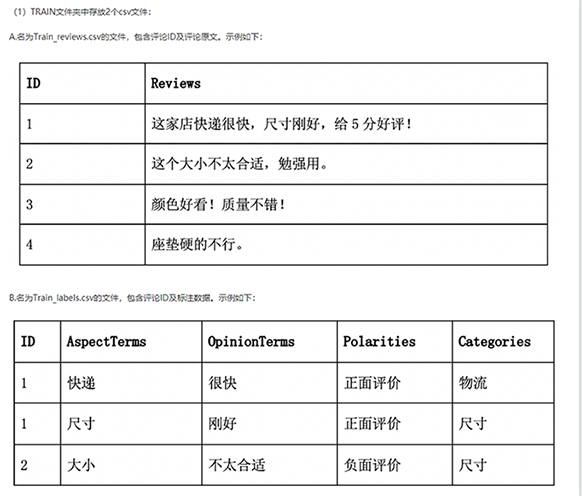
这里的一个核心问题就是修饰词和被修饰词的抽取,可以把它作为一个序列标注问题来解决。
2.模型和代码
我分别用keras尝试了bilstm+crf和bert+crf两种方法。bert的f1线下大概做到0.8就没抽出时间再做了,而bilstm我只做到了0.7。代码先放在这里,后续发现更好的优化方式再继续学习。
完整代码
3.CRF
简单介绍一下CRF(条件随机场)。《统计学习方法》中对条件随机场的定义:

通俗理解大概是Y_v的条件概率只与与它有边相连的结点有关。定义中涉及到了无向图,那先来看一下有向图的定义:
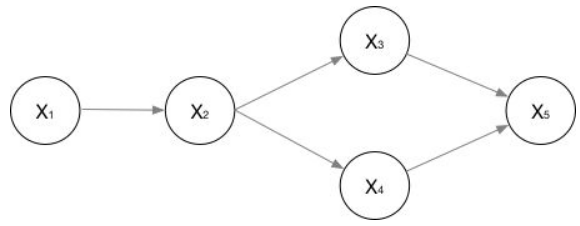
不难理解,它们的联合概率可表示如下:
贝叶斯网络就是有向的。
无向图一般就指马尔科夫网络::
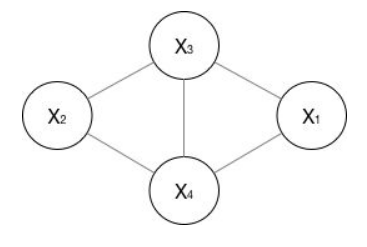
在无向图G=(V,E)中,V表示节点,E表示边之间的依赖关系。
可用因子分解P=(Y)将图的联合概率写为若干联合概率的乘积,具体的分法是将图分为若干个最大团。最大团的定义就是节点之间两两连通且不能加入任何一个新的节点使它成为一个更大的最大团。
如上图的联合概率可写为:
一般的形式为:
其中C为最大团,Z为归一化项,即:
称为势函数,要求为正,通常定义为指数函数:
现在看看CRF与HMM的区别:
HMM是生成模型,需要加入对状态概率分布的先验知识,而CRF是判别模型;HMM是概率有向图,CRF是概率无向图。
知道了什么是条件随机场,在序列标注问题中我们关注的是线性链条件随机场。Y是输出变量,表示标记序列,X是输入变量,表示需要标注的观测序列(也被记为状态序列)
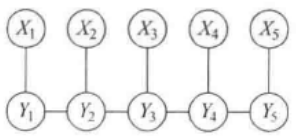
这样的线性条件随机场可表示为:
模型在学习时,利用训练数据集通过极大似然估计或者正则化的极大似然估计得到条件概率模型;预测时,对于给定的输入序列,求出使得条件概率最大的输出序列。
那么CRF的参数化是怎样的?
其中t为转移特征函数,表示观察变量从y_i-1到y_i的转移概率;s是状态特征函数,表示基于x,位置为i的变量对应的概率。λ和μ就是要学习的参数。
4.bilstm-crf
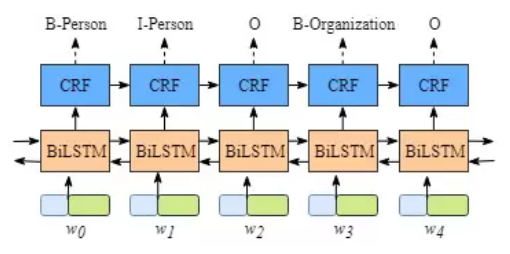
图中有5类标签:B-Person, I- Person,B-Organization,I-Organization, O
B意为实体的开始,I意为实体的中间内容,O意为实体之外。
图中最下面一行的输入中,每个单元均为词向量或字向量。如果先不看CRF层,只看biLSTM层的输出,如下:
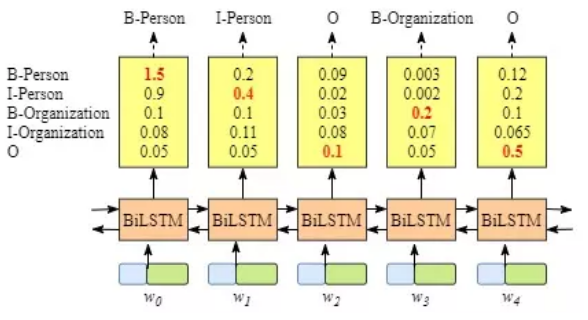
biLSTM层已经可以输出每个词为每个类别的得分,即只用biLSTM也可以作为一个序列标注的模型。但是此时预测可能出现明显错误的情况,如下:
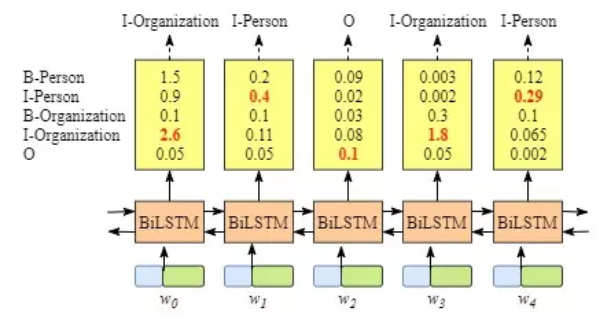
Person是不能接在I-Organization之后出现的。这样我们意识到生成的序列是应该受到一些约束的,如I不应直接出现在O之后,B开头的组织名不应该与I开头的人物名相连接等等。CRF层可以通过从训练数据中学习转移矩阵来保证预测标签的合法性。
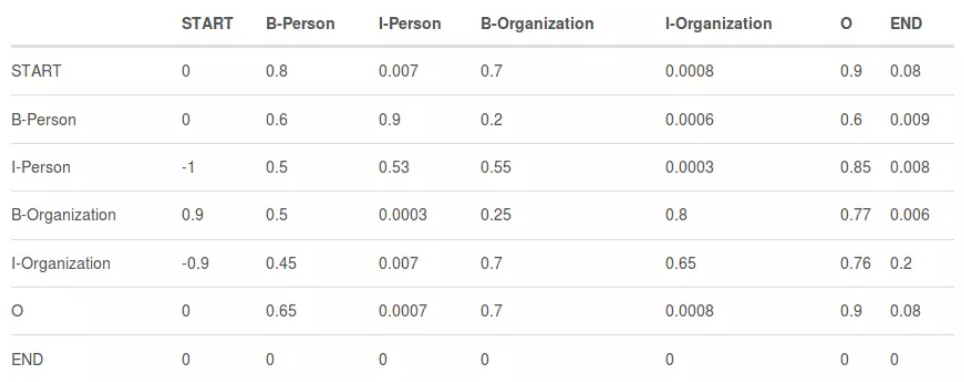
上图即为一个转移概率矩阵的例子。从中发现转移概率矩阵可学得很多信息,如句子从是以’B’或者’O’开始。那么LSTM和CRF层的打分是如何结合的呢?对于输入语句:
和一个预测序列:
模型得出的分数为:
其中A的部分为从
到
的转移概率,而P的部分为biLSTM得出的第i个词的标签为
的概率。在打分之后,对于所有可能的标签序列做softmax:
对以上概率取log,即得在训练时需maximize的式子:
显然,最终预测的标签结果为:
以上理论为以下论文3中提出。但是在我的代码中,是用crf直接使用bilstm的结果进行预测,而不是用上面两者相结合的打分模式。
代码参考:https://github.com/BrambleXu/aspect-term-extraction/blob/master/notebooks/bi-lstm-crf-embedding.ipynb
References:
1.BiLSTM模型中CRF层的运行原理
https://www.jianshu.com/p/97cb3b6db573
2.简明条件随机场CRF介绍(附带纯Keras实现)
https://spaces.ac.cn/archives/5542/comment-page-1
3.Neural Architectures for Named Entity Recognition
https://arxiv.org/pdf/1603.01360.pdf